5中IO模型(主要指网络io)
任何网络IO都会涉及到两个阶段:
A.等待数据准备完成
B.将数据从内核态拷贝到进程中。
五中IO模型的区别就在这两个阶段有所不同。
阻塞IO
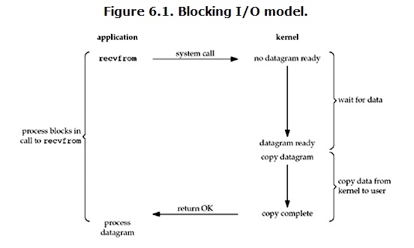
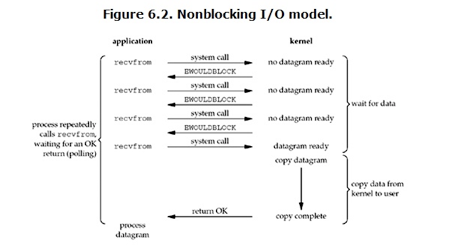
非阻塞IO
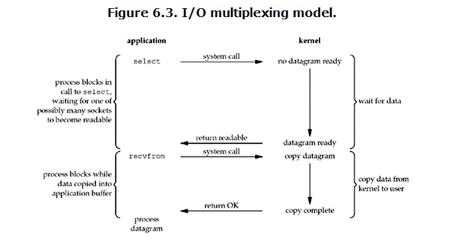
IO复用(也称 事件驱动IO)
异步IO
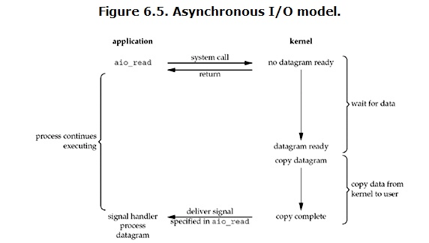
jdk是支持异步io
信号驱动IO(JAVA不支持)
常见io
Java NIO
-
传统io和nio的区别?
-
前者是面向流的,inputstream和outputstream只能单向传输数据。而后者是面向块面向缓冲的,效率更高一些。主要涉及到三类对象:Channel,Buffer,Selector。所有对channel的读写都必须通过buffer来完成
-
在网络io方面,前者采用的io模型是 阻塞io,一个线程同时只能监听一个socket;而后者采用的io模型是 io复用,可以支持一个线程同时监听多个socket连接。
-
还提供了其他一些功能:比如零拷贝,直接缓冲,内存映射
-
Channel
Channel主要分了两类: SelectableChannel(网络相关的); FileChannel(本地文件相关的)
-
SelectableChannel
- ServerSocketChannel(TCP,监听套接字)
- SocketChannel(TCP)
- DatagramChannel(UDP)
-
FileChannel
-
transferTo
-
transferFrom
这两个方法在操作系统的支持下可以实现零拷贝。一般情况下是将数据从内核态拷贝到用户态,然后再从用户态拷贝到目标通道的内核态中。这样就避免了内核空间拷贝到用户空间的内存拷贝操作,性能所以得到提升。
获取FileChannel对象的方式:
- 通过FileInputStream的getChannel方法得到
- 通过FileOutputStream的getChannel方法得到
- 通过RandomAccessFile的getChannel方法得到
三个方法的底层都是sendfile系统调用,通过man sendfile查看手册可知,sendfile的数据来源必须是一个文件(并不是很严格的说法,但肯定不能是套接字),数据的去向可以是任意的文件(普通的磁盘文件或者套接字等)

-

Buffer
-
读写Channel中的数据,都必须通过Buffer(缓冲区)进行操作
-
缓冲区本质上就是一个数组,常用的Buffer如下:
- CharBuffer
- ByteBuffer 长度固定,不能动态扩展和收缩
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
- MappedByteBuffer
public final Buffer flip() { limit = position; position = 0; mark = -1; return this; } public final Buffer clear() { position = 0; limit = capacity; mark = -1; return this; } public final Buffer rewind() { position = 0; mark = -1; return this; } public final Buffer mark() { mark = position; return this; } public final Buffer reset() { int m = mark; if (m < 0) throw new InvalidMarkException(); position = m; return this; } public abstract ByteBuffer compact(); public ByteBuffer compact() { System.arraycopy(hb, ix(position()), hb, ix(0), remaining()); position(remaining()); limit(capacity()); discardMark(); return this; } mark和reset配合使用 clear:恢复buffer初始状态 rewind:position位置重置 compact:把position到limit间的数据拷贝到开始位置,然后postion位置放到后面一个位置 同步异步:关注事件发生时的行为 阻塞非阻塞:关注等待事件事的状态 -
MappedByteBuffer (零拷贝)
通过FileChannel的map方法来得到MappedByteBuffer对象,使用它可以避免内核态到用户态和用户态到内核态的数据拷贝。底层实现是调用操作系统的mmap来实现的数据不会复制到用户空间,只在内核空间,但是应用程序可以直接操作该内存。
public MappedByteBuffer map(MapMode mode, long position, long size)MapMode有三种:
-
READ_ONLY : 只读
-
READ_WRITE : 读写
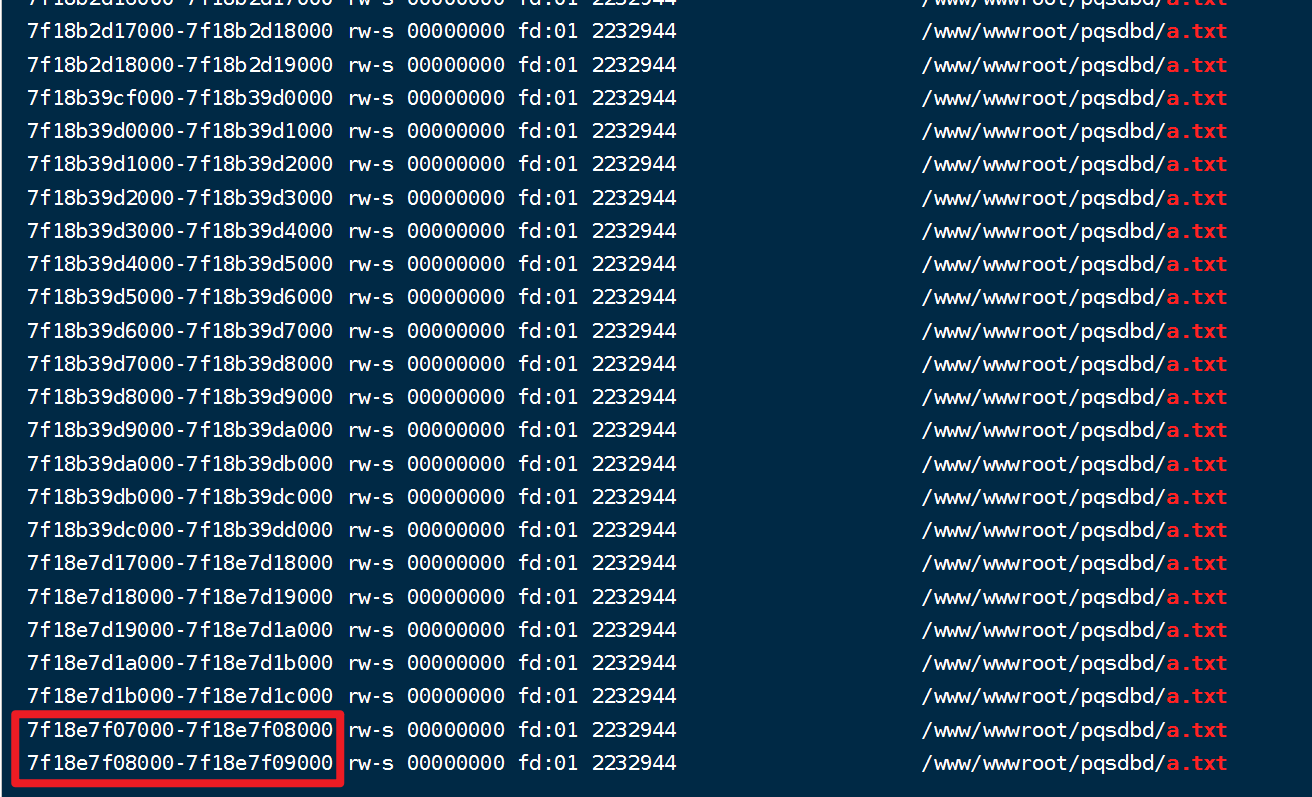
实验通过RandomAccessFile.getChannel().map方法,多次map同一个文件相同的为止,通过/proc/pid/maps可以看到多个多个映射的内存快,但通过gdb修改其中一个内存块,
然后dump memory另一个内存块,发现另一个内存块的内容也变了
文件内容也发生了变化 -
PRIVATE(专用) : 写的时候采用了copy-on-write(COW)策略,更改后的结果不会写入磁盘,所以只对自己可见
新增的三个方法:
-
force : 在READ_WRITE模式下,此方法对缓冲区所做的内容更改强制写入文件(注:只有在读写模式下才会有用)
-
load : 将缓冲区的内容载入物理内存,并返回该缓冲区的引用
-
isLoaded : 判断缓冲区的内容是否在物理内存,如果在则返回true,否则返回false
-
-
缓冲分片
slice()方法完成分片,对postion到limit之间的数据建立一个缓冲,两者共享同一个数据结构。 -
只读缓冲
asReadOnlyBuffer()完成只读设置,返回的缓冲与之前的缓冲共享同样的数据。 -
直接缓冲
通过直接缓冲可以避免一些数据拷贝操作 -
分散读和聚集写
对实现私有协议很有帮助。每一个消息被划分为固定长度的头部和固定长度的正文。您可以创建一个刚好可以容纳头部的缓冲区和另一个刚好可以容难正文的缓冲区。当您将它们放入一个数组中并使用分散读取来向它们读入消息时,头部和正文将整齐地划分到这两个缓冲区中

Reactor模式
https://zhuanlan.zhihu.com/p/92193290
SelectionKey
- 四种事件
- CONNECT
- ACCEPT
- READ
- WRITE
管道(pipe)
- 用于两个线程直接的单向数据传输
- 包含两个channel:sink,source。将数据写入sink channel ,从source channel读取数据。
- 原理如下:
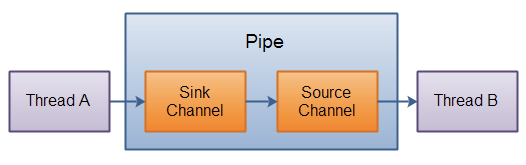
- 管道只存在于内存中,有点类似于生产者消费者问题。管道就是一个存储消息的地方,某些线程生产消息,某些线程消费消息。空间满的时候生产者等待,没有消息的时候消费者等待
//创建管道
Pipe pipe = Pipe.open();
//将数据写入sink channle
Pipe.SinkChannel sinkChannel = pipe.sink();
String newData = "New String to write to file...";
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
buf.put(newData.getBytes());
buf.flip();
while(buf.hasRemaining()) {
sinkChannel.write(buf);
}
//从source channel读取数据
Pipe.SourceChannel sourceChannel = pipe.source();
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = sourceChannel.read(buf);
Select Poll EPoll的区别
这三个都是多路复用io的实现方式,都可以监听多个文件描述符。
- select : 当发生了io事件时,它不知道具体是哪个发生了io事件,也不知道有几个,仅仅是知道,所以它就要采取轮训的方式来检查,所以时间复杂度是n.
- poll : poll和select其实没有太大区别,主要是poll采用了链表的数据结构,所以没有最大连接数的限制,而select则有这方面的限制,时间复杂度也是n
- epoll : 而采用epoll,当发生了io事件时,它不用通过轮训,它是直接知道是哪个发生了什么样的io事件,所以时间复杂度是1
扩展阅读:https://www.cnblogs.com/aspirant/p/9166944.html
MappedByteBuffer和PageCache的关系?是不是就是PageCache?
pagecache是操作系统层面做的一个优化。mmap则是把pagecache中的数据映射到用户空间的内存中。
这种方式相对于传统的文件读写方式就少了一个cpu-copy,也就是实现了零拷贝
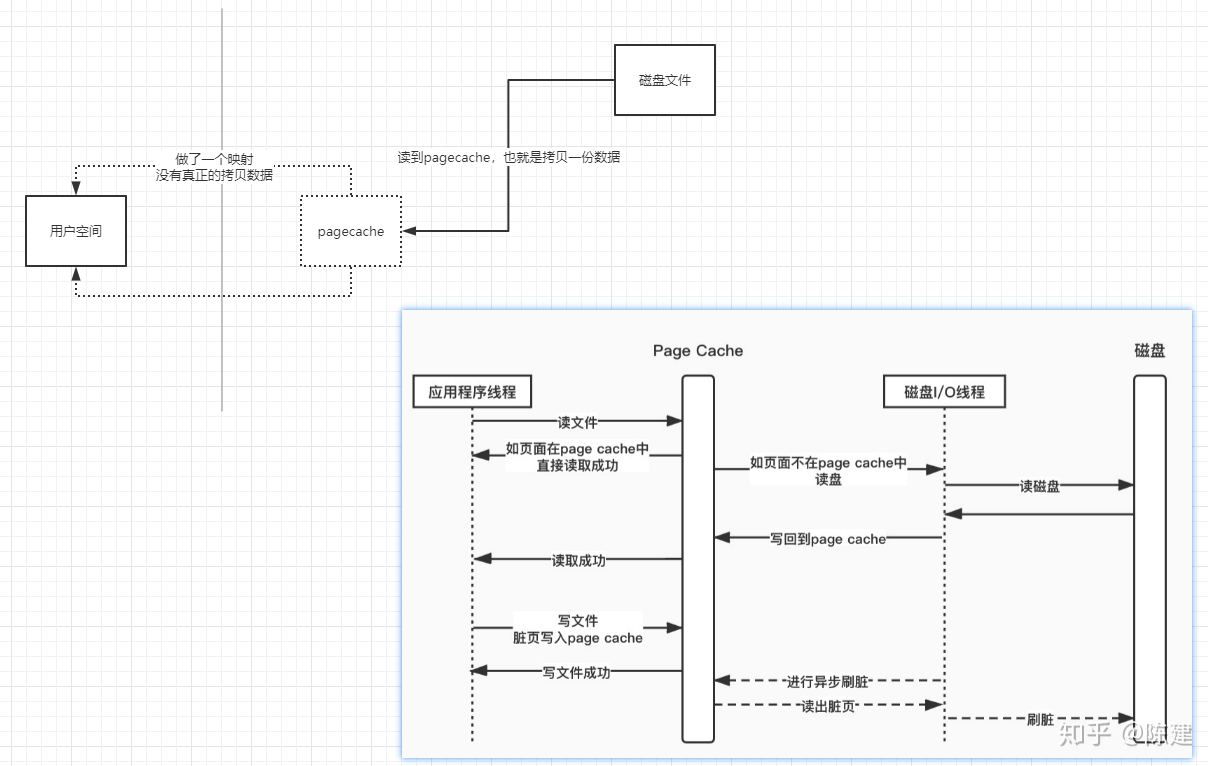
零拷贝
在Linux中,从一块存储拷贝到另外一块存储过程中避免了cpu-copy,这样的技术被称作零拷贝。
- 传统方式读取数据后并通过网络发送 所发生的数据拷贝(存在cpu-copy):
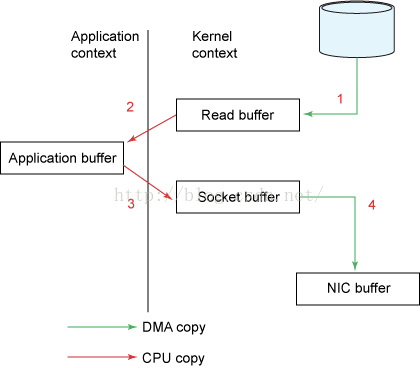
1. 发起read系统调用,执行了一次数据拷贝,从磁盘到内核空间
2. 然后将数据从内核空间拷贝至用户空间,发生第二次数据拷贝,read结束
3. 发起send系统调用,发生第三次数据拷贝,将数据从用户空间拷贝至内核空间(socket缓冲区)
4. 然后将数据从内核拷贝至协议引擎,发送第四次数据拷贝,send系统调用结束
4次上下文切换:
1. 发起read调用:从用户态切换到内核态
2. read调用结束:从内核态切换到用户态
3. 发起send调用:从用户态切换到内核态
4. send调用结束:从内核态切换到用户态
- 零拷贝方式(以FileChannel的transferTo方法为例,不存在cpu-copy)
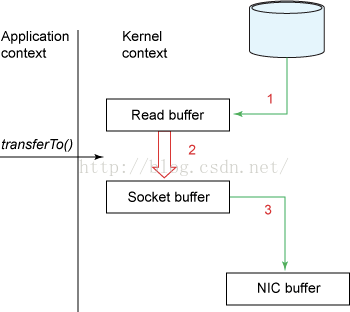
上图中的2,3步骤中涉及到的数据拷贝就省略了
2次上下文切换
linux内核2.4以后,socket缓冲区做了调整,如下图:
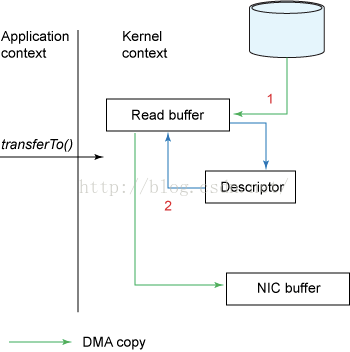
FileChannel的map方法底层是借助操作系统的mmap来实现的
FilaChannel的transferTo及transferFrom是借助操作系统的sendfile来实现的
mmap及sendfile都是操作系统实现零拷贝的方式
内存映射
直接缓冲
- DirectMemory的内存只有在 JVM执行 full gc 的时候才会被回收
- 默认情况下 MaxDirectMemorySize 的大小等于 Xmx的值
- 直接内存空间不足,会触发full gc.
Java AIO
系统推荐
- Notion笔记定时备份
- 记一次内存泄漏
- 在没有 telnet 和 nc 的世界里,如何优雅地判断端口是否通?
- JetBrains IDE 全破解
- Spring Cloud(一):服务治理技术概览【Finchley 版】
- kafka
- ShadowsockServer
- Paxos算法
- 异地多活
- RocketMQ
- sofajraft
- Docker隐射的端口外网不能访问
- 随机毒鸡汤:熬夜没什么大不了的,下辈子注意一点就好了!